Recent conversations on the recent slowdown in warming has inspired an animation on how models simulate this phenomenon, and what it means for the evolution of global temperatures over the next few decades.

UPDATE (18/01/13): A shorter version of the animation here.
{kind=link}
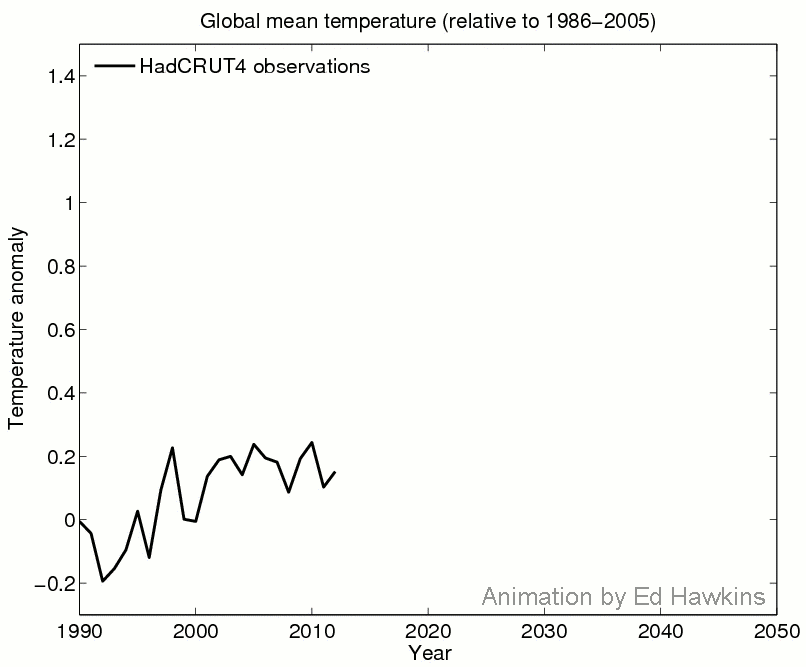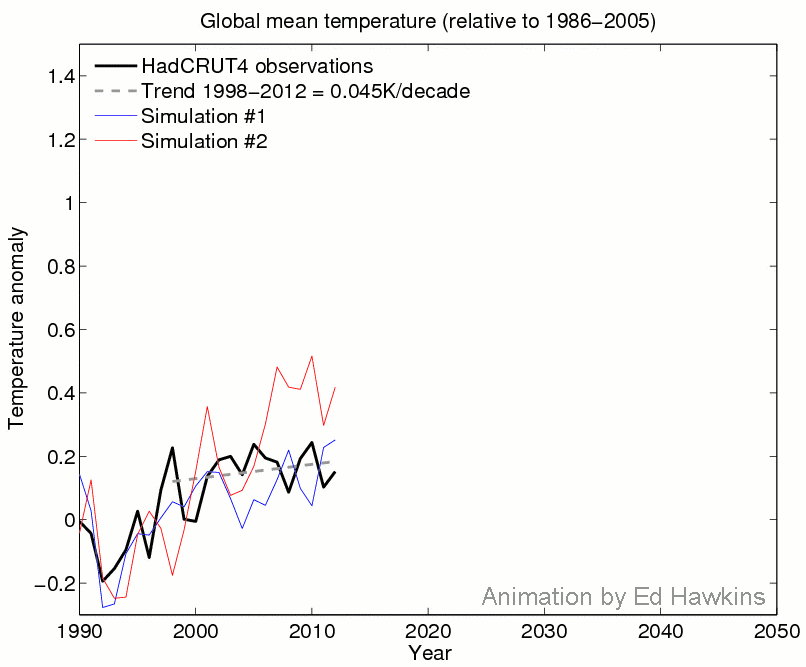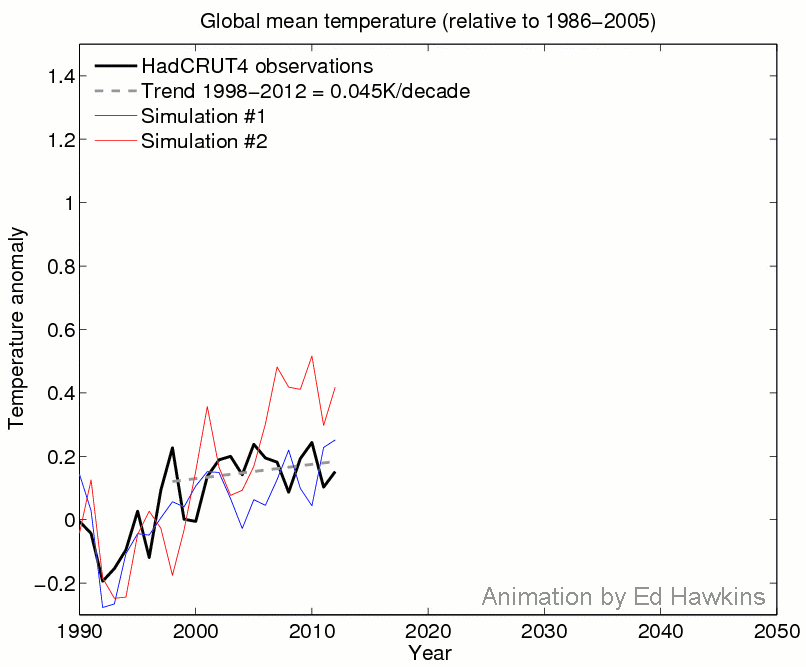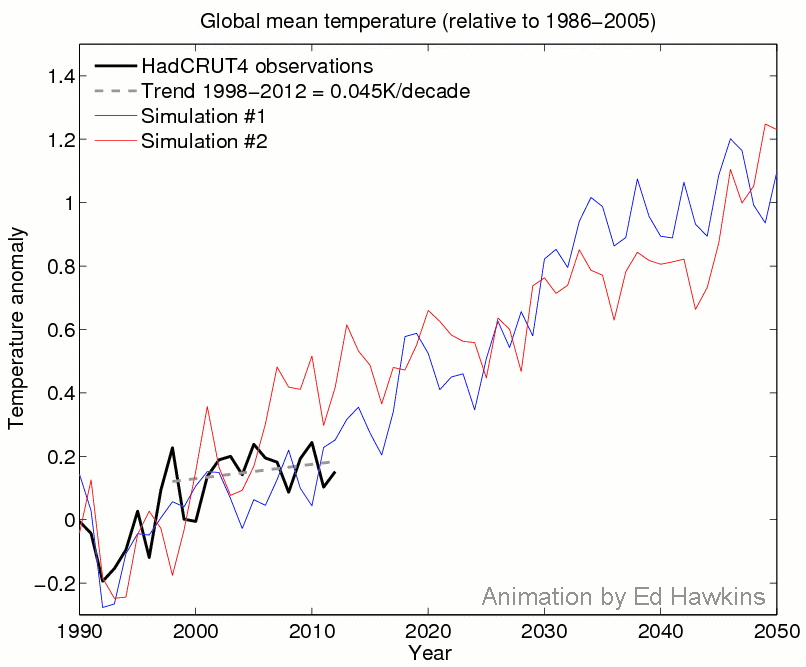
Explanation: The animation shows observations and two simulations with a climate model which only vary in their particular realisation of the weather, i.e. chaotic variability. A previous post has described how different realisations can produce very different outcomes for regional climates. However, the animation shows how global temperatures can evolve differently over the course of a century. For example, the blue simulation matches the observed trend over the most recent decade but warms more than the red simulation up to 2050. This demonstrates that a slowdown in warming is not inconsistent with future projections.
Technical details: Both simulations are using CSIRO Mk3.6, using the RCP6.0 scenario.
Hi Ed,
Model runs with different ‘weather’ conditions demonstrating that “a slowdown in warming is not inconsistent with future projections.” doesn’t tell us anything about the future evolution of surface temperature on our planet. This is because the model doesn’t represent the physical reality of the way the Earth’s climate operates.
Rog,
“doesn’t tell us anything about the future evolution of surface temperature on our planet”
Do you mean that the simulators are perfectly orthogonal to that which they simulate?
That I think would be an achievement; that all exhibited covariance were accidental with an expectation of zero.
I am increasingly struck by how “green” such notions are. The representation of climate as inestimable, incalculable, inimitable, as sublime: mankind as hapless servant.
Alex
We seem to confuse weather and climate especially when talking about climate change.
There is an almost universal acceptance of the notion that the observed increases in CO2 are entirely due to human activity and that these increases drive rises in global temperature. I have yet to see any evidence that this is in fact the case, CO2 levels rose from the fifties to the seventies at which time the next ice age was the big threat (temperatures were falling). Were global temperatures to rise then we would expect to see increased levels of CO2 in the atmosphere as a direct consequence of those rises.
Finally any model that shows consistently rising temperatures or exponentionally rising temperatures must be ignoring Stefan’s Law which says that heat is lost in proportion to the fourth power of the absolute temperature, setting up a very strong force to stop or at least reduce any increases.
tony,
I sincerely trust that they do indeed ignore Stefan’s Law. Its domain of applicability is not large and doesn’t include the Earth’s climate system.
It is an integration thing.
Alex
Just catching up on reading this blog.
In response to writing elsewhere by somebody who I strongly suspect is the same Tony (hi Tony 😉 ) I wrote a somewhat longer response than Alex’s on my own blog. I’d be interested to see any feedback from people who actually know what they’re talking about:
Stefan’s Law and AGW
Also:
Carbon Dioxide and Seawater
Ed D.
Hi,
What will the “simulations” do next?
Nice! I wonder how many will attempt to answer that question.
I think it does get close to the bottom of one of the issues.
There may be something unknown about their future, yet if they are deterministic there is nothing uncertain about them. Nethertheless, prior to that knowledge we can consider how we should use inference to guide us in estimating the likelihood of different futures. Given that there be no real uncertainty, we can reveal the future (run the simulation) and see how well we performed.
We can construct some simpler, and tractable model of the simulator, estimate probability functions for its parameters using the output already available and our prejudices, and then run forwards. Hopefully giving us a trajectory and some concomitant uncertainty.
In those terms, that final uncertainty is dependent on how well those parameters are constrained by the available data and our judgement. This in turn reflects back on our ignorance of the sensitivity of the simulator to its own parameters.
The stated problem about simulators, as I have represented it, is an analogue of the climate problem but with a difference.
Given a particular simulator: what can we infer about the propability distribution of its parameters, given real world evidence concomitant with real world uncertainties?
How big a section of the simulators parameter space is plausible?
The difference being, for the real world we have to wait for the future in real time, and that future external influences are yet to be revealed.
I think I could make an attempt at answering the stated question but my skill would be determined by the availability of data. To determine the model parameters I sould like lots (100s) of simulator runs against the same forcings in order to infer a response function and a noise function and even then I doubt it would be skillful for a prkection longer than a proportion of the temporal length of the forced period, maybe a 1/4 or so, call that ~30 years.
Given only a single run, I could still develop a noise function provided data for a long (1000+ years) stabilisation period was available, but my uncertainty in the response (to forcing) function would be large. This being a simpler question than the real world one, I ought to be able to give tighter uncertainties about a simulator, given just one run, than the simulator could give about the real world; at least insofar as their is no observational uncertainty in simulated outcomes.
One thing I would have very little confidence in would be estimating a climate sensitivity for the simulator. Knowing something about the likelihood of outcomes over 30 years or even a length as long as the industrial period cannot inform me as to the nature of the response function beyond such periods unless I prescribe the unconstrained part of the response function based on some notions I may happen to have knocking around about how to extrapolate the function for a further thousand years or so.
Now I am pretty sure that I have read a paper (one of yours?) recently that deals with the existence of “sweet spots”, e.g. that under certain circumstances, we can have more confidence in the middling term, than either of the short or long terms. Although perhaps due to different circumstances (the considerations I have stated) I think this would be the case for any projections I could make about the simulator’s future.
I know for certain that I could not determine the actual trajectory of any simulation, I am stating the obvious for clarity. More interesting I suspect that my best judgement about my uncertainty in that trajectory would would give it a large range, for the reasons given.
Finally, I do favour further exploration of the parameter space of the real world for I think it might give us useful information. There is currently some speculation doing the rounds on the back of a black carbon assessment paper (the one that singularly I need to read before commenting on). I suggest those interested go back and read or revisit the Hansen et al (2000?) Alternative Scenario paper. (The one that got him attacked by the Green Meanies.) Doing something about combustion emissions is not just a good thing in itself, it removes or diminishes some of the parameters about which we are least confident and would do so relatively quickly. We could already have been enjoying a somewhat cleaner world, and a significantly more certain future.
Alex
Thanks Alex
1) Agree that reducing black carbon seems like a ‘win-win’ situation.
2) The ‘sweet spot’ was first mentioned in Cox & Stephenson (2007), but a paper by Hawkins & Sutton (2009) did explore this too. Essentially the signal to uncertainty ratio in the predictions may increase initially, but shrink after mid-century.
cheers,
Ed.
With respect to point 1), I suggest banning all forest fires with immediate effect*. You could follow this up with a ban on dung burning for cooking. This will be a ‘win-win’ too; dead people (from eating uncooked food) don’t cook! Finally, I recommend a ban on deliberate outdoor biomass burning – stubble, forestry discards, garden waste, pointless annual rituals, etc.
Brave new world – no pain, no gain.
* this may require a ban on lightning.
“What will the simulations do next?”
Simple, whatever their creators program and tune them to do. They’ll only show us those results which are consistent with their preconceptions however.
Hi Rog,
I think we commonly hold a preconception to be something like:
“An opinion or conception formed in advance of adequate knowledge or experience, especially a prejudice or bias.” (thefreedictionary)
In the case of predicting an outcome:
how do we turn our preconceptions into conceptions?
Some may baulk at the notion that we express a prejudice or a bias. However a prejudice is a preconception and a bias an inclination which is in turn a prejudice, so the pair add little to the overall meaning.
That leaves the question of adequacy, which is a needs dependent evaluation. If our need is prefect precognition then we will only ever have preconceptions.
If we only wish to confine oursleves to the domain of plausible futures then we can make progress.
One individual simulated outcome by itself is, in my usage, a determination. It is extraoridinarily unlikely to come to pass. A prediction, is in my usage, something quite different, a representation of a weighted range of outcomes, a probability judgement. Such can never be proved right on a single realisation but could be proved wrong, if the realisation had been given a zero probability.
Such predictions are your flexible friends. They can be judged to be a fair assessment by weighing the implied precision, or lack thereof, against our degree of knowledge or lack thereof, our ignorance.
I think we can, but perhaps rarely do, make such predictions, carefully weighted to express the full, but no more, extent of our ignorance as we perceive it. Then we could perhaps say that our conceptions do not exceed the adequacy of our knowledge and experience, some combination of specific evidence and general wisdom.
I note that I have described a subjective process. I can conceive of no other and quote Jonty Rougier:
“If they think that science is objective, then they cannot be doing any!”
http://allmodelsarewrong.com/2012/11/06/many-dimensions-to-life-and-science/#comment-1493
We can attempt to make subjective predictions, that are fair representation of the depth, but no more, of our ignorance. They would be subjectively true.
Again this is in my and a once more common usage of the word true. To be loyal and faithful. In this case being true to ourselves, to being honest.
The usage of true is a topic in itself and in science, but I must stop.
Alex
“Simple, whatever their creators program and tune them to do. They’ll only show us those results which are consistent with their preconceptions however.”
If this were true, perhaps some skeptic climatologist should construct a GCM that can plausibly explain historical climate without the enhanced greenhouse effect? ;o)
That’s been done many times. The temperature record is ‘not inconsistent with’ a random walk.
I specified a physics-based model (a GCM), not a statistical one. Also “not inconsistent with” is a *much* weaker statement that “plausibly explained by”.
I am able to cook an omlette, an observation that is “not inconsistent” with me being a top chef, but it does not imply that I even have any useful skill in the kitchen (I don’t). Similarly a “random walk” (while not inconsistent with the observations) does not “plausibly explain” the temperature record as in this case “random” just means “the things we don’t know about”.
Falsificationism suggests that we should probably abandon models that are seriously inconsistent with the observations (taking into account statistical issues, such as multiple hypothesis testing). However, amongst the non-falsified hypotheses, we should apportion our belief in their truth according to the plausibility with which the explain the observations (including their parsimony). Now if skeptics could produce a physics based model of the climate without the enhanced greenhouse effect, that explained both current and historical climate better than current GCMs, it would be a very powerful argument for them. However the fact that climate skeptics seem to rely so much on statistical models for me is suggestive of a fairly weak position. It also suggests that physics-based models (of course) cannot be made to say whatever the programmer wants them to say.
Hehe. I used to work on 3D computer models of the plasma in the sun’s interior and its interaction with the magnetic field. There are various parameters that either aren’t known very well or are known but the correct physical values can’t be reached computationally, so you have to choose unrealistic values. Then you have to choose your initial conditions and boundary conditions. After a while I saw that some people were choosing things so that the numerical results supported their pet theory. I even realised that I had done this in one of my simulations. So I stopped working in that field.
Hi Paul,
If you were implying that the temperature record in not inconsistent with integrated iid noise, I think that can be shown to stretch the meaning of inconsistent beyond its normal sense. It you imply that the record is not inconsistent with some choice of noise model with LTP then that is close to a truism. I think even could produce candidate models that ape the global temperature record to that degree.
The classic random walk, integrated noise, i.e. noise convoluted with the Heaviside step function would imply something unphysical for a temperature record, as I think would convolution with any function whose own integral was unbounded.
Rejecting such cases will still leave us with a wealth of linear transformations formed as convolutes with time invariant response functions to work with. Amongst them will be candidates with which the record is not inconsistent.
There is substantial and reasoned resistance to the notion that our default postion should include the assumption that the record is explicable in terms of transformed noise. To do so brings in to question what, if any, interpretation we can give to the concept of significance. Cohn and Lins have raised this question and I broadly agree yet I do not think that such implies an insuperable barrier to inference. It does imply that we have to be cautious, We need to be able to understand and track the origin and independence of other lines of evidence.
By way of illustration I suggest the following alternatives.
I have an interesting finding in the form of a series that I cannot explain. I could take the issue, in outline only, to theorists in the relevant disciplines and ask them to respond with whatever the current theory suggests and then compare that with my data. If they can explain any substantial proportion of the variance then I may have a partial or even a complete explication. Alternatively I could post the data in the public domain and invite responses.
I think it is clear that the two approaches, the first with the specific data withheld and the second with it widely distributed should result in a material difference to the significance I assign to the responses.
Our inability to run confirmatory real world climate experiments with changed parameters is a substantial difficulty, so we need to think differently. I think a key point is establishing were and in what ways our thinking risks being, and hence should be assumed to be, circular. What would our best theories indicate, “out of the box”? In practical terms this currently requires assuming that everything that could be calibrated to the record has been, and discounting the significance of any match between the theories and reality substantially. A problem being not that any such calibration has or hasn’t taken place but that the process remains opaque.
There is a suspicion that the science has been curve-fitting, and that any alternative curve-fitting is equally valid. That is not I think the case, that is my prejudice, my opinion. I will continue to assign significance based not so much on the strength of a match but on the strength of the theory, the amount of independent evidence that the theory explains.
If I take myself back five decades I return to a time when the theory was almost exclusively derived from sources independent of the temperature record and of course derived from sources totally independent of the subsequent period. That cruder theory can be returned to. It has implications that have proved to be explanatory. The explanation may be a good deal weaker than what has been done since but it retains a significance due to its independence, something that I have found to be increasingly difficult to quantify in subsequent periods.
I find myself in the awkward position where I would assign more significance to the explanatory power of the simulations if they performed less well in hindcast.
Alex
A nice demonstration of how short-term variability disappears into insignificance in the long term! But a few questions re known unknowns:
– What’s not in the models with respect to positive feedback? E.g. permafrost melt, clathrate release, desertification? Are there any guesses (best or otherwise) on how big/bas these positive feedbacks might be?
– Likewise, what’s not in the models with respect to negative feedbacks? (I can’t think of any examples!) Any guesses on much these factors (if any) might damp future change?
– Is there anything special about the year 2100 as a stopping point? How high can temperatures go before the assumptions in the models falls apart?
I realise these are slightly(?) off topic…
Hi Pete,
The positive feedbacks you mention (except perhaps clathrates) are included to some extent, but with considerable uncertainty in their magnitude. There is also uncertainty in the negative feedbacks we know about, such as some cloud aspects.
2100 is used as it is a round number – the simulations could (and some do) go further, but there are (computing) limits to the quantity of simulations that can be performed, and there tend to be higher priority simulations than beyond 2100.
cheers,
Ed.
Hi,
I think that the CSIRO Mk3 series can/does use a MOSES II land surface, so it could/should include the above bar clathrates plus vegetation e.g. TRIFFID. 🙂
Who makes up these acronyms?
Alex
Ed, Alex, thanks for enlightenment.
I trust Ed is right about “higher priority simulations than beyond 2100”. I just get a bit wound up when people fall into the assumption that the planet will gently stop at whatever temperature we hit at the right side of the graphcs. deltaT=4C will probably be nasty but not impossible. But continue at deltaT=0.4C/decade for much beyond and the biosphere is likely to get very, very dull.
Pete,
I think that the following could be of use, it is a response model, e.g. given a scenario it will emulate the underlying trend for various climate simulators as a curve, without dealing with the variance about the curve. Unless/until it is updated it is based on AR4 (or earlier) models and A1B to B2 scenarios, but it does allow them to be extended into the distant future, e.g. 2500. For some of the scenarios the temperature does markedly increase for centuries to come.
JCM (Java Climate Model) from l’Université catholique de Louvain
http://jcm.climatemodel.info/
It has a lot of complex features but if I steer clear of them it is reasonably intuitive to use.
It is the only model of its type of which I know, perhaps there are better more current ones.
*****
I find it obvious that the response timescales of the various systems are as important as the temperature scales. Put simply, I am sure that we are participants, not disinterested observers, and that it is an interplay between, climate, technological, and societal timescales that defines the trajectory on the basis of preceived harm/benefit. In that way of thinking, the absolute rise in temperatures would be secondary to any overshoot of temperatues beyond what may come to be seem retrospectively to have been sensible both in amount and duration.
That may be characterised as being very pessimistically reactive, but I am not so sure. The degree to which we are proactive should be influenced by the degree to which we can tollerate overshoot and in turn by our expectation of its amount and duration.
If XºC is intollerable and the return time to below XºC is Y decades and the peak overshoot is TºC we can make some judgement as to the wisdom of it all. As I see it, both the degree of overshoot and its duration are priimarily functions of the rate of increase in temperatures and the response timescales.
I also suspect that such an approach will play to the strength of the models (climate, technological and societal). The relevant time horizon is quite short, hopefully only a few decades of overshoot would occur. And it is the trajectory not the longterm equillibrium that is key, I suggest that we have a much better grip on the medium scale trajectories than the ellusive equillibrium.
The reason that this is not pessimistic is in its consequences. If it turns out our current rates of increase would give rise to overshoots on the timescale of a human lifespan or even a generation that may for many people be cause for proaction. The thought that we may not be able to extricate in a timely fashion is a daunting one. Personal perceptions of thresholds vary, some may think that we are already into overshoot, others may be much more cautious, but it may be that we share some more common notion as to the timescale to recover from overshoot.
I find it very difficult to assess the strength and agility of the societal feedback loop. I am sure that it is the ultimate, the decisive feedback loop provided it is not overstretched.
Whilst we don’t know, or don’t agree on where XºC is on the temperatures scale, we can still produce argument based on how fast the systems can react and how fast we are approaching.
Alex
I don’t really care what the simulations do next..
what will the planet / observed temps do next..
if the current flat trend occurs for a few years, (as the Met Office new decadal forecast suggests) what then for the ‘simulations.. as temps will be below them.
or even is temps cool by a rate 0.1C per decade (which is not outside the Met Office prediction range!)
the simulations seem to have a linear trend of about 0.2C per decade for the rest of the century, is this really credible.
This was interesting, Ed, and has of course been pointed out many times.
It shows that the climate (short term, AKA weather) will do pretty much what it wants to, and that this does not prove (or disprove) anything. It shows that the present (recent) temperatures are well in the realm of what models would predict.
But I am curious, since you cannot influence the cahotic weather short term, how many realisations did you have to run to get the lower trend the last century matching the last decade?
Hi Jonas,
The simulations I used came from the CSIRO-3.6.0 model, which has the largest number of CMIP5 realisations, with 10 per scenario. I picked two members from one of these scenarios which had different time evolutions, one of which matched the observations fairly well.
Previously I discussed an analysis by another group, using an older model and scenario, which ran 40 realisations, nicely demonstrating the role of variability in that particular model.
Thanks,
Ed.
I wonder if it’s possible to build something like the “normal distribution” generator (which demonstrates how many runs it takes before a nice clean bell curve emerges).
Something that instead distributes the falling pingpong balls to illustrate a trend over time, maybe by, I dunno, moving the pins slightly during the run?
Here’s that “normal distribution” device (“Galton machine”)demonstrating an outlier (rare) run
That’s taken from this post.
Here’s a Galton machine video (warning autoplay dramatic music and financial overtomes): https://www.youtube.com/watch?v=9xUBhhM4vbM
Another nice one: https://www.youtube.com/watch?v=3m4bxse2JEQ
So — if you wanted a comparable machine to illustrate trends — I guess you’d change the spacing of the round posts, or the angle and spacing for those using square posts.
You’d get the same kind of illustration — multiple runs would come out like the examples you show at the top of the page.
I think this awareness that runs using the same starting conditions come out in a range of variations around a probability distribution is _very_ hard for people to understand, and maybe even harder to explain (at the fifth grade reading level, which is where I aim as I think it’s slightly below the US national average literacy level).