When comparing global temperatures estimated from observations with climate model simulations it is necessary to compare ‘apples with apples’. Previous posts have discussed the issues of incomplete observational data, but a new paper by Cowtan et al. quantifies the influence of different observational data types.
Usually, global temperatures from climate models use simulated near-surface air temperatures (SATs). However, observations use SATs measured over land, and sea-surface temperatures (SSTs) measured over the ocean and are not spatially complete. The comparison of the global averages of these two different quantities is therefore not like-with-like.
This new analysis gets closer to a like-with-like comparison by sampling the models with the same spatial coverage as the observations, and by using the simulated SSTs over the ocean, blended with the SATs over the land. Note that more background, along with the code & data is available for this study.
Because SSTs tend to warm slightly slower than SATs over the ocean, this reduces the warming trend in the simulated estimates of global temperature, bringing them closer to the observations over the past decade. This simple correction accounts for about one third of the difference between the observations and simulations (top panel). Note that the difference between the red & blue lines is only due to the blending, not the incomplete spatial coverage.
In addition, there have been a few small volcanic eruptions and a reduction in the solar forcing since 2005, which were not included in the CMIP5 simulations. This new analysis applies a correction to the radiative forcings derived by Schmidt et al. (2014) to further improve the like-with-like nature of the comparison (bottom panel). This adjustment brings the simulations and observations even closer together.
Combined, the apparent discrepancy between observations and simulations of global temperature over the past 15 years can be partly explained by the way the comparison is done (about a third), by the incorrect radiative forcings (about a third) and the rest is either due to climate variability or because the models are slightly over sensitive on average. But, the room for the latter effect is now much smaller.
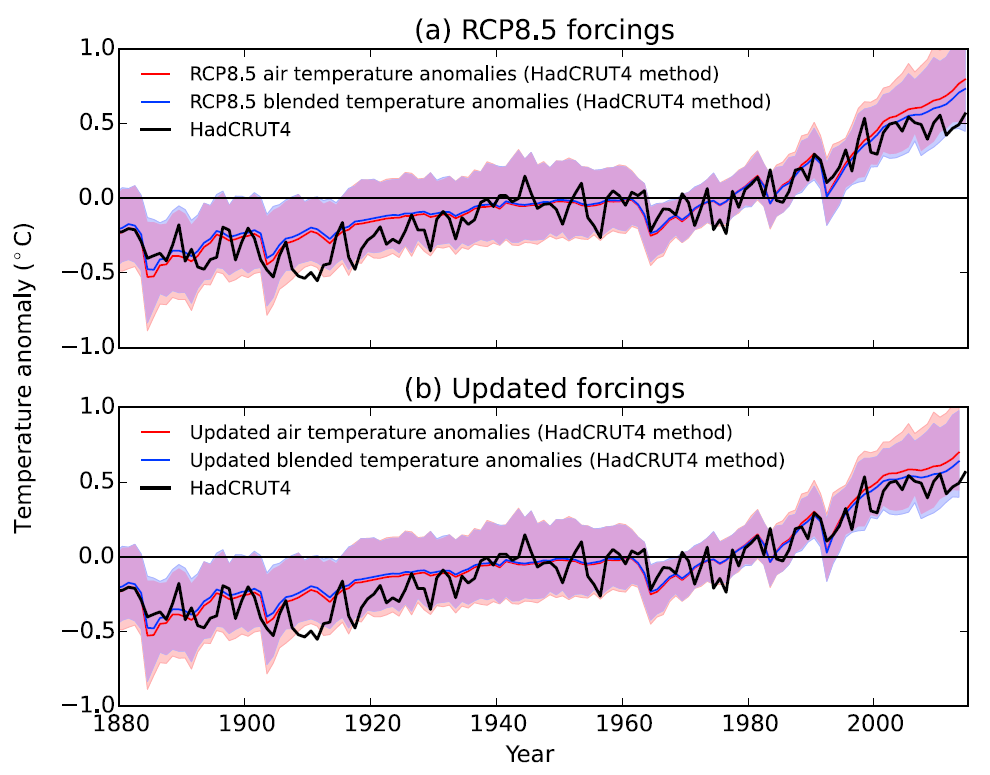
Show how important details become when you are interested in the last tenth of a degree over just a decade in a fast changing world.
This global-warming-has-stopped debate must be one of the weirdest debates in my life. People who typically doubt at least half of the warming, making a fuss out of such a minute deviation.
Hey Victor,
Figure 2 in Cowtan et al. shows the expected long-term effect of this. Using some kind of blended SST/surface air temperature approach like current observations do, leads to temperatures about 0.2 C lower globally by 2100 in models, relative to using air temperatures.
Ed refers to this being “because SSTs tend to warm slightly slower than SATs over the ocean”, which suggests it’s a transient result, but I suspect it might be at least partly an equilibrium response related to the changing surface-air energy balance.
MarkR, even in 2100 that 0.2°C for the RCP8.5, which shows an average temperature increase of 4°C is less than 5%.
I would be very happy if we would one day trust the temperature changes with that kind of accuracy.
But then RCP8.5 is a worst case scenario, and not business as usual. What happens In 2100 if the world would embrace nuclear, like Lynas and Hansen are advocating?
If emissions are reduced dramatically by whatever method, then the projected warming is much reduced – closer to 2C above pre-industrial temperatures. This is RCP2.6.
cheers,
Ed.
Hans Erren, RCP8.5 is the scenario for the people who say CO2 is life, who claim that warming is a net benefit, who claim that we cannot lift people out of poverty without centralized coal power plants, who claim that a modern renewable energy system would bring us back to the middle ages.
More to the point the 0.2°C MarkR talked about was for RCP8.5, thus I should also compare it to RCP8.5. This is a post about comparing apples with apples after all.
Nice work, Ed et al! It confirms my crude calculations and speculations in your earlier blog post..
I have an additional question. The observational data seems to warm faster than the blended CMIP5 average in the period before WW2. Can this be caused by to little “bucket correction? As far as I know the bucket correction has been done by comparing SST and MAT ( or NMAT). However, if the global temperature is rising fast, like in the period 1910-1940, then the MAT should rise faster than SST, according to the findings in the present study.
Do you think that this will lead to a reevaluation and adjustment of pre-1940 SST, which presumably would improve the fit between historical model runs and observations?
Hi Olof,
The early 20th century warming is still a bit of a puzzle. Some of it is due to a recovery from a series of volcanic eruptions at the end of the 19th century, some due to early GHGs, and some is natural variability. There are possible issues with data corrections during WW2 where the SST observations changed a lot, but the warming from 1900-1930s is probably real. Remember also that we don’t expect the observations to follow the CMIP5 mean – we expect the observations to look like a single ensemble member with deviations from the mean.
cheers,
Ed.
Thanks Ed,
I also believe that the warming of 1910-1940 is real and can be explained by forcings; solar radiation, no major volcanic events, but possibly also 60-year cycles bringing more el Ninos. If models produce 60-year cycles they would surely not do it synchronously, hence it can not be seen in model means.
However, when global temperatures change fast, the change in SST should lag MAT, which in turn lags Land air temps. The strange thing is that SST almost increase faster than land air temp during 1910-1940:
http://www.woodfortrees.org/plot/crutem4vgl/mean:120/plot/hadsst3gl/mean:120
Kevin Cowtan wrote about bucket correction, being one of the larger uncertainties in early SST and global temperatures here:
http://www.skepticalscience.com/kevin_cowtan_agu_fall_2014.html
Also, I guess that the present apples-to-apples theme fits under the lable “thermal inertia” in that article. Using oranges as apples, ie ignoring the thermal inertia of the seas, has likely resulted in too low estimates of climate sensitivity in Otto et al, Lewis and Curry, etc.
Hi Ed
thanks for the interesting new paper and blog post.
Could you say something about aerosol forcing (not volcanic)? Did you adjust that as well to for example the latest estimates in AR5?
Thanks, Marcel
Hi Marcel,
Yes – the bottom panel includes the Schmidt et al. updates to GHG, solar & volcanic forcings, but does not include tropospheric aerosols. Schmidt et al. quantified that the aerosol updates would also cool the models, but with larger uncertainties.
In the text, the Cowtan et al. paper states that if the aerosol updates had been included, then the forcings, masking and observation type effects would have reduced the discrepancy between models and observations by 68%, rather than 54% as shown.
cheers,
Ed.
Ed
I think Marcel’s question was about the AR5 best estimate rather than the Schmidt revisions. It seems to me that the figure used in your paper must be quite a long way adrift of the AR5 best estimate and even further from, say, Bjorn Stevens.
It seems to me that the figure used in your paper must be quite a long way adrift of the AR5 best estimate
Why?
and even further from, say, Bjorn Stevens.
IIRC, Bjorn Stevens didn’t provide a best estimate, but simply inferred that it was unlikely to be more negative than about -1W/m^2.
Ed, you say in response to BishopHill
“2) There is lots of ongoing research to quantify aerosol forcing. You seem to be very keen to believe a single study which may fit your belief in a low TCR. It might be right. It might not.”
but you also say in the post
“This new analysis applies a correction to the radiative forcings derived by Schmidt et al. (2014)”
It would appear that the paper does exactly what you guard against. The study chooses one particular aerosol estimate and imposes a correction from this single estimate. It appears that the study isn’t testing the results against the uncertainty that exists in aerosol estimates.
Hi HR,
That is categorically incorrect. If you read the paper, then we deliberately do not use the aerosol forcing corrections as derived by Schmidt et al. in the figure because of the uncertainties involved. We also describe that we checked that the Schmidt et al. numbers agree with a separate study from Huber & Knutti (2014).
Ed.
I think there is some confusion about how aerosol ‘forcing’ is implemented then.
In the top panel, each GCM derives it’s own response to aerosols from the assumed aerosol concentrations (or emissions) in the historical and RCP8.5 scenarios. Therefore each GCM has a different radiative forcing from the aerosols. In the bottom panel, there is no change to this – only to the GHG, solar and volcanic terms.
This is different to the energy balance model type approach which has to use a value for the forcing itself, for which values are available in the RCPs, but they are derived from simpler models.
cheers,
Ed.
Sure, but if the aerosol forcing derived is very different to IPCC best estimate and “implausible”, if Stevens is to be believed, then the models are effectively being flattered by the comparison in your paper.
BH,
1) The aerosol forcings from each GCM should not necessarily be the same as any ‘best estimate’ – they should be in the range of likely values.
2) There is lots of ongoing research to quantify aerosol forcing. You seem to be very keen to believe a single study which may fit your belief in a low TCR. It might be right. It might not.
3) Out study is to quantify the effect of doing a proper comparison. I don’t understand your comment about flattering models?
cheers,
Ed.
I think there are quite a few observational estimates of AF that are much lower than the GCMs.
BH,
I think there are quite a few observational estimates of AF that are much lower than the GCMs.
I think that is over-stating the case. If you read Chapter 7 and 8 of WGI you will find that they determined the overall aerosol forcing by combining both satellite observations and models. Neither was regarded as sufficient to make an overall assessment. The satellite estimates were indeed lower than the model estimates, but that doesn’t mean that one should trust the satellite estimates more than the models.
In fact, chapter 8 explicitly says
Despite the large uncertainty range, there is a high confidence that aerosols have offset a substantial portion of WMGHG global mean forcing.
Also, the AF in the models has quite a large range, going from – AFAIA – around -0.35W/m^2 to around -1.6W/m^2.
If you wanted to eliminate the bias supposedly introduced in global temperature data as a result of measuring SSTs and not actual marine surface air surface temperatures – and minimise problems associated with data coverage – would you not simply choose to look at the Lower Troposphere temperature record? Data over land and sea is like-for-like, oranges to oranges, so to speak and coverage is much greater. In order to then see how the climate models are performing, one could simply compare UAH and RSS directly with CMIP5 multimodel projections of lower tropospheric temperature.
Hi Jaime,
Yes, that should be done AS WELL. The surface record is far longer than the lower tropospheric records so more useful in that sense, and it is where we live of course.
Also, comparing the lower tropospheric temperatures in an apples-to-apples way is not simple either – there are also coverage issues as the satellites do not see the poles, and there are weighting functions for different heights in the atmosphere. All of which could be applied, but it is not as straightforward as you suggest.
cheers,
Ed.
Hi Ed,
Yes, I was aware of the fact that the satellites don’t cover the poles too well, which is why I said ‘minimise’ and not eliminate re. uncertainty due to coverage. Even so, the coverage of the satellite data has to be a significant improvement over surface temperature measurements. Yes, of course, the data only goes back to 78/79, but this fully includes the crucial period of rapid surface warming followed by the significant slowdown in 98 and encompasses most of that period in our history when the radiative forcing from GHG concentrations could be said to be of much greater importance, so we would expect the modeled trend to more closely reflect actuality. But I’m glad you agree that it would be a good idea to compare the satellite data with model predictions as well, just for context.
Jaime Jessop, do you know of an error estimate for the satellite temperature trend? One that shows that its trend is more accurate than the surface trend?
Satellites are great for their global overview, but not so wonderful when it comes to trends. New satellites and new designs are continually introduced, which have different calibrations. The satellites drift in space leading to artificial trend, which are actually the much larger daily cycle of temperature. Early satellites did not maintain the same height. The corrections for such data problems are a large part of the trend the satellite retrievals show. They would thus have to be very accurate.
As far as I know, this work on the satellite trend uncertainty is not done yet. Not surprising given that tropospheric temperatures are not very important for humans and we have longer datasets for the surface temperature, which are expected to be more accurate. Thus it is logical that only a handful of scientists work on this data, mostly as a side job.
blog post by Carl Mears, a Senior Scientist at RSS writes:
Given the high intrinsic trend uncertainties and the small amount of work put into making these datasets accurate, the enthusiasm of the mitigation sceptics for these datasets is scientifically surprising.
Victor,
” . . . do you know of an error estimate for the satellite temperature trend? One that shows that its trend is more accurate than the surface trend?”
I am not aware of any. Likewise, are you aware of any robust study which shows that the surface temperature trends are more accurate than the satellite trends? Both measurement methods have their drawbacks and uncertainties, but overall, LT satellite and surface temperature trends are in remarkable agreement over the entire period since 1979, with only minor discrepancies – primarily associated with El Nino events. Before the ‘pause-busting’ very recent adjustments were made to GISS/NCDC/NOAA, all of the datasets showed no significant warming from about Jan 2002.
In fact, it is only very recently that satellite and surface temperature measurements appear to be diverging significantly. The cause of this divergence is very much open to debate.
http://www.climate4you.com/images/AllInOneQC1-2-3GlobalMonthlyTempSince1979.gif
The argument that we don’t live in the lower troposphere, we live on the surface, therefore the surface temperature data is far more relevant seems to me somewhat slightly absurd. LT is a weighted mean which runs from the surface up to about 10km I believe, with the definite emphasis on lower altitudes, about 3km being the optimum I think. Most obviously, the LT is intimately connected and highly correlated with trends in surface temperatures as is reflected in the graph above.
VV: ” . . . do you know of an error estimate for the satellite temperature trend? One that shows that its trend is more accurate than the surface trend?”
Jaime Jessop: “I am not aware of any. Likewise, are you aware of any robust study which shows that the surface temperature trends are more accurate than the satellite trends?”
No, I am not aware of a study showing that surface temperature trend is more accurate than the trend of a dataset for which the trend uncertainty is unknown.
If you are interested in the trend uncertainty of surface stations, I can recommend a good article by Williams et al. (2012). I also wrote one, which had some weak points, which we will try to make better in the International Surface Temperature Initiative. I think the real uncertainty in the surface trends is larger than these two studies show, but at least we have such estimates and there is ongoing work to estimate them better.
(If there is something that makes me doubt John Christy of UAH it is his recent congressional testimony in which he was unable to see any problems with his own work and blamed models for any differences. Normally scientists liberally mention caveats, especially when it comes to their own work, where they know the caveats the best.)
And if you think that the surface temperature trend is not reliable due to urbanization: there have been numerous studies into this and the effect is very small. The scrutiny that went into the surface temperatures is order of magnitude larger than that of the tropospheric temperatures.
The tropical hotspot that causes the larger tropospheric trends is seen in a recent newly homogenized radiosonde dataset. It is seen in tropospheric winds. The amplification is seen on shorter time scales. The tropical hotspot is seen in models (for any kind of warming). The most probable resolution of this minor discrepancy is thus that the trend of the satellite temperature is a bit wrong. I call this “minor” because no one would expect this trend to be particularly reliable.
I am naturally happy to let myself be convinced by a scientific article that studies the trend uncertainties in the satellite data are so small that there is a real problem. To put more confidence in the satellite tropospheric temperature trend than in the surface trend at this moment does not fit to the weight of the evidence.
Feel free to add to our understanding of the data. The current code to process UAHv6 is secret, but the spaghetti code to produce the previous version with a stronger trend is nowadays available. All data and code used to produce the surface station temperatures can be downloaded on the homepage of GHCNv3.
To your graph: it is best not to give too much weight to differences over short periods, especially at the end of the data. It takes time to discover data problems and it takes time to be able to discover data problems. Arguments are stronger when they consider all of the data. That the year to year variability is similar in all datasets does not mean that the long-term trends are okay, that is much more difficult with all the changes in the way the measurements were performed.
Maybe I should mention that with HadCRUT4 you even get a large ensemble of temperature fields that help you to study whether the uncertainties are important for a specific question. It takes into account the uncertainty due to measurement errors, sampling (that we do not have measurements everywhere) and various non-climatic changes (inhomogeneities). Again this is not perfect, but it is there and I know of nothing comparable for satellite temperatures.
“but this fully includes the crucial period of rapid surface warming followed by the significant slowdown in 98”
I don’t see any evidence of a significant slowdown in any of the temperature series. Using Kevin Cowtan’s trend tool which uses an ARMA(1,1) noise model:
http://skepticalscience.com/trend.php
The RSS trends are:
1979–latest: 0.121 +- 0.064 C/decade
1979–1998: 0.082 +- 0.115 C/decade
1998–latest: -0.033 +- 0.184 C/decade
There is no statistical evidence of any difference from the long-term trend or of any change at 1998 or any other year I checked.
If there is such a thing as a climatological temperature (which makes a lot of sense), then the only way you can imply trend changes or a “slowdown” in warming is to slice up the temperature record, ignore prior knowledge of climatological temperature and allow magical temperature jumps just before your selected period starts. If you fit a trend from 1979–1998 your estimate of the climatological RSS temperature anomaly at the beginning of 1998 is 0.05 C. Then if you fit a trend from 1998–present your climatological temperature anomaly for 1998 is 0.28 C. The cut-up-the-record technique implies some kind of magical 0.23 C jump in climatological temperature just before the selected “slowdown” supposedly begins.
The reason it looks like a flattening is that this ignores the prior knowledge about the true background temperature, and linear regression doesn’t know about things like extreme El Ninos. Using this technique you can make very nice escalator graphs but that’s not very physically sensible.
“The reason it looks like a flattening is that this ignores the prior knowledge about the true background temperature, and linear regression doesn’t know about things like extreme El Ninos.”
You’ve lost me there I’m afraid. I have no idea what the ‘true backgound temperature’ is, or who is supposed to have had prior knowledge of it. The reason it looks like a flattening is that it IS a flattening. Likewise, the reason that the temperature looks like it is inclining steeply from 79 to 98 is that it IS rising quite rapidly. These are physical facts; they have physical explanations. GHG forcing of the temperature in the lower atmosphere and at the surface – which according to the IPCC was predominantly responsible for the 79 to 98 rapid warming – didn’t just take a break after 98; something reduced it to near zero, and it wasn’t vexatious dissection of the temp record; it was something physical. Hence climate scientists embarked on the search for the ‘missing heat’ – which they still have as yet to pin down.
Jaime Jessop,
There is no statistical difference between any of the trends, from 1979–1998, from 1998–2015 or from 1979–2015. The trend is like an estimate of the change in the background mean temperature of the climate, and according to the data we can’t say that warming has slowed or stopped. We can’t even rule out an acceleration in the true background trend, although that is much less likely according to the raw stats.
If you want to assert a slowdown, then you need to also assert that there are magical jumps in temperature that take place just before you decide that the slowdown starts. I suppose it’s possible that these things are real but they’re such an extreme outcome that you’d need some extraordinary evidence to show that they’re real.
Neat. But what is the justification for the very large uncertainty in the very small trend from 1998 to present compared to the very much smaller uncertainty in the greater trend from 1979 to present? Is it directly related to uncertainty in the actual data?
Is it directly related to uncertainty in the actual data?
No, it’s mainly to do with the variability in the data itself. If you have a dataset with variability that doesn’t change much with time, then the uncertainty in the trend increases as you decrease the time interval over which you calculate the trend.
The Skeptical Science Trend Calculator illustrates this nicely (just determine trends over different time intervals).
Ah, right, yes. I’ve read a bit more about the SkS trend uncertainty calculator. So there may be a statistically valid case to be made for looking at the shorter trend and concluding that, statistically speaking, it is not significant. However, if we come back to the real world, we note that there are several ‘statistically insignificant’ hiatus periods in the long temperature record since 1850, which punctuate the long term secular warming trend. In the real world, natural multi-decadal variability can be invoked to explain these ‘statistically insignificant’ hiatus periods. What I find most fascinating is that the current slowdown/hiatus, according to a paper released in Sept 2014, is unique in the record in that it is very likely due to a combination of multi-decadal variability AND a reduction in the secular warming trend. I quote:
” However, they found that the current hiatus period is, for the first time, particularly strongly influenced by changes in the secular trend, which shows a strong acceleration from 1992-2001 and a deceleration from 2002 to 2013. Such rapid and strong fluctuations in the secular warming rate are unprecedented.”
Here is the paper, which analyses the Hadcrut temperature record using spectral analysis. To me, this is a far more useful – and scientifically meaningful – way of looking at the current pause, in contrast to simply labeling it as ‘statistically insignificant’.
http://journals.plos.org/plosone/article?id=10.1371/journal.pone.0107222
We should not forget that a continuation of the long-term linear trend during the “hiatus years” is not enough. The models show an accelerating warming trend, for the period 2000-2030 the trend is about 0.27 C/decade, a “blended” approach would bring the trend down by maybe 0.03. The global observational indices have a trend of about 0.13 since year 2000, so they have to speed up to follow the models up to 2030. Of course, it is slightly easier for apples to follow apples than the speedier oranges.
This recent century lag in observations vs models could be caused by natural variability, e g 60 year cycles with relatively more la Ninas right now, pumping heat down in deeper ocean layers.
Jaime Jessop:
We can find some differences in historical trends. In HadCRUT4 the post-1970 trend (+0.17+-0.03 C/decade) is larger than the full-record trend (+0.05+-0.01 C/dec) or the 1900-1945 trend (+0.11+-0.03 C/dec), for example. From 1940—1970 the highest possible “true” trend is 0.03 C/decade. These largely match changes in forcing so it seems there might be something real going on behind them.
Unfortunately stats are stupid, they don’t know what’s causing things. For example, a few things stick out from the Marcias paper:
1) Figure 3, the “trend” seems to go up then down, but the confidence intervals are wide enough that recent values don’t seem to be significantly different from older values.
2) Figure 2 shows cool periods due to “natural variability” roughly from 1890–1920 (during which Krakatoa and Santa Maria erupted) and roughly 1960—1990 (including Mt Agung, El Chichon). 4 of the 5 of the large tropical eruptions (the other is Pinatubo, 1991) that are known to cause cooling possibly contributed to their ‘natural variability’ calculations. In this case, their internal variability probably isn’t just the internal variability we normally think of (ocean cycles etc) and it’ll be a bad guide to the future unless volcanism matches historical patterns.
3) This is possibly true for other changes. 1940—1970 increases in aerosols largely cancelled out greenhouse gas forcing so we don’t expect much of a true trend there, although they report one (cancelled out by ‘natural variability’). Their early 20th century uptick in ‘natural variability’ is when solar activity increased. The recent downtick in ‘natural variability’ is when solar activity decreased and background volcanism increased.
Just by coincidence, it looks like their natural variability matches a lot of the variability in radiative forcing from volcanoes, the Sun & aerosols. This needs to be done properly, but it suggests that 1) their ‘natural variability’ probably isn’t entirely natural (it might include human-caused aerosols) and 2) is a bad guide to the future unless solar & volcanic activity repeat the same patterns.
I think this is one of the reasons why we need physical models to really get into this, but this comment is already long enough and I need to do some work right now!
Mark, thanks for the detailed reply.
“In this case, their internal variability probably isn’t just the internal variability we normally think of (ocean cycles etc) and it’ll be a bad guide to the future unless volcanism matches historical patterns. . . . .
. . . . . . Just by coincidence, it looks like their natural variability matches a lot of the variability in radiative forcing from volcanoes, the Sun & aerosols.”
There is a considerable body of research which suggests a link between volcanic and seismic activity and solar activity. It is also likely that solar activity affects ENSO/PDO/AMO. So it might be difficult to disentangle these effects from one another. What seems fairly certain is that the rhythmic ups and downs of the oceanic cycles seem to be ‘hardwired’ into the terrestrial system, where external forcings (e.g. solar/GHGs) may ‘excite’ particular harmonics/modes of vibration, over which may be superimposed a characteristically ‘noisy’ (but not totally random) fingerprint of (negative) aerosol forcings.
Whatever the case, Ed and others believe that the secular warming trend from 1850 is almost totally due to anthropogenic GHG emissions. I’m not so convinced and if the paper I referenced is correct and the ST is actually decreasing during the current hiatus, after markedly accelerating during the latter part of the 20th century, it brings into question just what is forcing the secular trend, given that GHG forcings have increased exponentially and are predicted to continue to rise thus unless deep emissions cuts are imposed. It also brings into question just how ‘insignificant’ internal variability is and how significant it might possibly become if climate sensitivity turns out to be at the lower end of estimates. Then what if external solar forcing turns out to be rather more significant than presumed and – most vitally – turns out to have significant interactions with ‘internal’ variability? With solar activity predicted to decrease markedly within the next few decades – perhaps to Maunder Minimum levels, the Earth-Sun laboratory looks certain to afford us the unique opportunity to test such hypotheses. But AGW exponents are intent on pushing the ‘we must act now to avoid catastrophe’ meme supposedly backed up by ‘hard scientific evidence’.
Jaime Jessop,
Before we can use the satellite records in this way we have to reconcile why they do not agree as well with one another as the observational datasets. Then you have to explain why there are still biases being suggested in UAH according to the STAR group, Sherwoods paper and Chedley’s work.
Hi Ed,
Have D&A studies used global SAT fields rather than model SST? If so, do you have any idea what difference it could make to substitute in model SSTs?
Hi Paul,
I believe most (but not all) D&A studies have used SATs, but masked to the observational coverage. I understand there are ongoing studies to examine the SST/SAT effect in more detail. It will probably not make much difference, given that the correction is due to both the masking and the observational type differences.
cheers,
Ed.
Hi Ed,
“Because SSTs tend to warm slightly slower than SATs over the ocean”
Can you give a physical explanation as to why this should be so ?
Surely it can’t be true that long term trends could be different between SST and SAT as temperature differences would rapidly diverge. It is afterall the trend which determines anomaly warming.
As a second point. How accurately do models represent the topology of land measurements? With the oceans we are talking about a difference of just 2m between SST and SAT. However land stations can differ in altitude by more than 4000m and within each 5×5 grid cell there will be contributions from stations which differ by up to 1000m in altitude. How can this be any different ?
One can’t help but get the impression that the search for any hidden biases is just a one way street – to make warming trends higher. Why do we never see any correction which actually reduce warming ?
Hi Clive,
If I may comment… Living in a seasonal climate, it comes quite natural that air warms faster than water in the spring, and cools faster than water in the autumn.
I guess that the modelers have put some reasonable physics into the models that mimics this larger thermal inertia of sea vs air.
Regarding different altitudes of land stations, I dont think it is a major problem since they are dealing with anomalies, not absolute temperatures. I believe it is more important that all stations are 2 m above ground.
Your third point, corrections/updates are not only a one way street. The biggest of them all, the bucket correction, warmed the past.
As I remember, GHCN v 3.3 slightly took down recent values and trends of Gistemp. Also, the recent revision of CRUTEM 4.4 has warmed the period 1885-1950, lowering the 20th century trend..
http://www.metoffice.gov.uk/hadobs/crutem4/data/update_diagnostics/global_n+s.gif
Regarding the cooling of 1850-1880, this period is not very reliable, due to poor data coverage, and the anthropogenic forcing was insignificant back then.
Hi Olaf, your reply to Clive makes good sense and I took a look at the crutem4 graph. This leads me to ask a question (as I use meteorological models and re-analysis data on a daily basis) if the data assimilation used in these models is “state of the art” why is there such a “disconnect” with the climatological?
http://www.ecmwf.int/en/research/climate-reanalysis
OK the anomalies are probably 1981/2010 referenced and it is a shorter data period but I’m genuinely puzzled. The NCEP version of reanalysis tells the same story, I guess they share the same data.
Hi Olaf,
I think you really mean land warms faster than water in spring and cools faster than water in autumn. Air by itself cannot warm from direct solar radiation. It is insignificant 2m above the ocean.
For the sake of the argument though let’s assume that the yearly SAT averaged over seasons really is say 0.5C warmer than SST. It still should make no difference to the global result, unless the long term trend of SAT is different to SST. This is due to the following reason.
Hadcrut4/CRUTEM4 calculate the global average of the temperature anomaly not asbolute temperature, and such offsets are subtracted out in the local normalisation. Otherwise CRUTEM4 would be completely wrong as it avergaes the anomalies from different altitudes together. There is an underlying assumption that global warming can be measured by the change relative to a fixed monthly normal period eg. 1961-1990. For example the change in average temperature measured at 2000m in Colarado can be geographically averged with the change in temperature at sea-level in California.
There are some subtle biases introduced by using anomalies which are seldom mentioned. One of these is the UHI effect which most people simply assumes makes cities warmer than the surrounding countryside. This is true but once a city has developed the temperature anomaly is the same as the countryside. It is only during a period of rapid growth that the anomaly changes, and this makes the city cooler in the past. The overall UHI effect in CRUTEM4 is mostly to cool the past. A good example of this is Sao Paolo which grew from a small village into one of the world’s largest cities in under 100y. By 1961 it was already ‘warm’. The normalisation subtracts this warmth off the anomaly thereby making Sao Paolo appear colder than the surroundings in the early 20th century. See graph here. Sao Paolo doesn’t measure global warming at all. It measures the effect of rapid urbanisation. There are many other examples – Shanghai, Beijing, Moscow etc.
Returning to the SAT/SST difference. The CMIP5 updated forcing curves for SST from SAT look suspicious to me because they show no difference at all before 1990, after which they seem to increasingly diverge until 2014. How can that be? What physics could explain an effect that only switches on after the normalisation period 1961-1990?
I think this may be another underlying bias of using anomalies relative to a fixed seasonal normalisation period (1961-1990).
Stephen, I am not a specialist on reanalyses, but I have noticed that global 2 m temps from those are more similar to observational 2 m datasets than to mixed land 2m/SST datasets. That is, the warmest year is not 2014, but somewhere between 2002 and 2010.
Clive, it is true that direct sunlight doesn’t heat air very much. If we also ignore the infamous backradiation from greenhouse gases, or transport of warm air from other places, it is still possible for sunlight to warm air directly over the sea faster than “SST”(temperature 1-10 m depth).
If you look at the following picture, the daytime surface skin temperature can be much higher than the layer below, thus likely heating the air directly above faster than the “SST”
http://ghrsst-pp.metoffice.com/pages/sst_definitions/sst_definitions.png
I have no problem with the UHI, it only affects minor areas of the globe. The BEST team has shown that the UHI effect has a negative trend the last 50 years. I also believe that GISS overcompensates UHI by the double measures, GHCN homogenisation, and their own UHI correction.
Also, if UHI is real, why remove it? UHI is also ” anthropogenic warming” although not by increased greenhouse effect. The important thing is that UHI affected stations proportionally represent UHI affected areas, when calculating global averages.
The use of adjustment to a base period when comparing different datasets will commonly create a “waist” at its center, and plumes diverging in both directions.
I dont think that this is the only cause of divergence between between SST and SAT after 1976 (base period center). It may also ( likely) be a result of the rapidly increasing greenhouse gas forcing during that period.
Look at the following graf with GIstemp dTS (a global 2m air index) and Gistemp loti ( a blended SST/2 m land index)
http://www.woodfortrees.org/plot/gistemp/mean:60/plot/gistemp-dts/mean:60
they follow each other very well from 1910 to 1980 ( forget the messy WW2), and then start to diverge, demonstrating that SAT warms faster than SST also in real world, not only in the models…
Hi Olaf,
“Stephen, I am not a specialist on reanalyses, but I have noticed that global 2 m temps from those are more similar to observational 2 m datasets than to mixed land 2m/SST datasets. That is, the warmest year is not 2014, but somewhere between 2002 and 2010.”
That does seem to be the case but anyway the “warmest year” is a bit of a red herring in a unequivocal rising trend ie it is only to be expected to be more recently likely than in the past.
The reason I like the reanalysis data is because it is very “noisy” and nuanced to understanding much shorter term effects within the climate system. ENSO for one.
Interestingly Kevin Trenberth has picked up on a more “nuanced” take on the “hiatus” itself.
http://www.sciencemag.org/content/349/6249/691.full
Dare I suggest that without climate models there would be NO hiatus, just noise without a benchmark?
As a postscript I note that Dr Ryan Maue’s versions of the NCEP global reanalysis temp data from the Coupled Forecast System V2 is available freely here;
http://models.weatherbell.com/temperature.php
OK Ed it ain’t apples to apples(different methodologies) but it also dovetails with Kevin Trenberth’s recent article.
I see a real case for making more use of reanalysis data from the main providers, it is so “multi-dimensional ” in representing the noisy complexity of the Earth system.
Olaf,
I dissagree. Air is warmed by the skin surface through IR, conduction, evaporation (latent heat) and convection transfering heat upward. So yes the skin surface warms fast during the day and then cools fast at night, and therefore the air at 2m must also follow suit. Direct sunlight absorbed by any water vapour or ozone in the air is tiny compared to the convective and latent heat flows from the surface. Why would an enhanced GHE change this balance? As SST warms so should SAT warm in perfect synch. Can anyone explain physically why it shouldn’t ? Do the models predict that the lapse rate changes?
The BEST result for UHI look convincing. When I tried a similar analysis by removing stations based just on population I got a similar result. However I realised only recently why this technique cannot change recent warming trends as measured by temperature anomalies. CRUTEM4 results post 1976 are unchanged. There is something far more subtle going on.
On land the effect is to make it appear that the 19th and early 20th century were cooler relatitve to 1976. I believe it is simply a result of the population increasing from 1.5 billion to 7 billion and the encroachment on wether stations. NCDC pair-wise auto-corrections don’t help either.
http://clivebest.com/blog/wp-content/uploads/2015/06/C4-Xclude-cities.png
It is not really that a large effect when combined with Ocean data but it is still of the same order of magnitude as the SST/SAT issue discussed above.
I worry that insufficient critical analysis is being done before rushing out the next paper which “explains” the discrepency between models and data.
I’m thinking similar to Clive here and I too am confused as to why differences in the way the sea surface and the air directly above it are heated should result in any significant difference in the long term trend. The long term trend is surely governed by changes in short wave solar radiation (intrinsic solar variability and/or variations in cloud cover) and increases in long wave IR radiation from accumulating GHGs. How can a short term (diurnal/seasonal) difference in energy uptake between sea level air (which is directly heated via conduction/latent heat of evaporation transferred from the sea surface) result in a long term trend difference? The only way I can see this being a vague possibility is if you argue that downwelling long wave IR radiation is heating the air just above the oceans slightly quicker than the ocean surface (over the long term), the surface which presumably absorbs some heat from the air in contact with it, in a reversal of the normal process of daytime heating. But this seems a bit of a stretch of the imagination too. Is there something rather obvious I’ve missed?
OK, if we leave the thermal inertia thing aside…
I looked at data from TAO buoys, that report both 1 m SST and 2 m MAT, and it looks like MAT on average is 0,5-1 degree cooler than SST. I guess that this difference is even larger in cooler sea regions. Thus, on average sea surface warms the air above it.
If greenhouse gases increase, the amount of heat trapped by air above Sea surface should increase, which in turn decrease the heat gradient from sea to air.
However, there should be a limit for how small the temperature difference between sea and air can be, ie it can’t be zero. The divergence of SST and MAT anomalies predicted by models is only a few tenths of a degree to year 2100, so the model predictions are not unrealistic.
To be honest, I barely understand what I am writing about :-), but couldn’t this case with MAT anomalies rising faster than SST anomalies, be a specific ” fingerprint” of increased greenhouse effect (and not a temperature increase due to increased solar radiation)? The models predict it, the question is if it is there in the real world?
Anyway, it is always safe to compare apples to apples as far as possible, then we dont have to assume that MAT always follow SST closely..
Hi Clive – yes, the lapse rate changes in GCM simulations with increased forcing – it is actually a negative feedback (see figure 9.43 in AR5). And, of course, the SSTs are influenced by the ocean below as well as the atmosphere above. I think it would be good to look at the regional & seasonal pattern of the global mean differences – I suspect this might help disentangle what is going on.
cheers,
Ed.
Yes I know the lapse rate changes with increased CO2 forcing. The height of the tropopause should also increase. However I was really only talking about the first 2m height above sea level. I cannot see any reason at all why the temperature gradient should have increased since 1990. Can you?
Yet that is what is really implied by the two graphs from Cowton et al. that you show above. By eye it looks like models predict a net relative increase of global SAT-SST difference 0.15C. That represents an energy increase of ~ 5*10^12 joules in just 25 years ! Hence my doubts whether this result can really be valid.
Perhaps I have missed something?
Hi Clive,
Cowtan et al.’s results suggest that 2m air temperatures warm more quickly than SSTs, so shouldn’t the near-surface air temperature gradient decrease? In which case, that affects the surface energy balance.
I just picked MIROC5 and CanESM2 as they have low and high sensible heat responses to warming and I used their 1pctCO2 runs to calculate sensible & latent heat flux changes in response to temperature change under increasing CO2. The sensitivities are:
MIROC5 (sensible heat) -0.23 W m-2 K-1 (latent heat) +1.15 W m-2 K-1
CanESM2 (sensible heat) -0.54 W m-2 K-1 (latent heat) +1.15 W m-2 K-1
Let’s assume unsaturated air and a 1 K warming. The water has a non-radiative net cooling increase of 0.92 W m-2 in MIROC5 and 0.61 W m-2 in CanESM2. For unsaturated air there’s no latent heat release in the layer but the sensible heat is felt by the bottom 2 metres. The air experiences an extra non-radiative net cooling just from the reduced sensible heat flux of 0.23 W m-2 in MIROC5 and -0.54 W m-2 in CanESM2.
In both cases the non-radiative cooling feedback is larger for the ocean surface than the near-surface air, so you’d expect a higher temperature response from the air.
This is piled with assumptions and there are other factors to consider (1) radiative changes (2) heat flux to the deeper ocean which is transient and (3) horizontal transport. These are more difficult to work out, but (3) should cause changes consistent with Cowtan et al.’s results and (2) is less relevant except in the way that it feeds into (3).
So from my reading of the physics, the Cowtan et al. results are sensible.
Oh, and there’s one more thing and perhaps someone could point out if I missed something obvious here.
Increases in precipitation under warming seem to be limited by the rate at which the atmosphere can cool by radiation in order to offset the increased latent heat. This restricts modelled precip growth to between about 1 and 3% per Kelvin of warming. With water vapour increasing by 7% per Kelvin, this suggests a slowdown in the rate at which moist air ascends in order to conserve mass.
Since mean changes in moisture flux through the 2 metre height in the atmosphere must be pretty close to changes in total precipitation, this slowdown occurs throughout the 2 metre layer and fits with the patterns found by Cowtan et al since you’d expect something like a decline in the surface-air interface temperature difference.
Of course, this all comes from models right now so we need to bring in other evidence to be sure. The physics looks like it fits though.
Hi Mark,
The only way to resolve this is to download and install the software from Kevin Cowton. However, to do this I need to install Python, Netcdf-python,and all the CMIP5 results for whch I need an extra password. Even then I would need his help to check the results. Since I am travelling in Australia at the moment this will be a little difficult.
There is one extra detail that I am confused about. Cowtan writes that about 1/3 of the model-data dicrepency is due to SST/SAT difference and 1/3 due to small volcanoes (reduced forcing – Gavin Schmidt). So in reality the SST-SAT difference is actually small and recent. Furthermore he says that any difference in ‘anomalies’ only appeared since the middle of the last decade. One reason for this (he implies) is that reduced coverage of Sea Ice in the Arctic ( a favourite topic of his) has effectively increased the sea surface layer, because air temperaures are used over ice (like land). This can’t be the case for data used by HADSST3 since to calculate anomalies one must have a normalised period from 1961-1990. In other words open sea is required prior to 1990. Perhaps he is talking about the models.
I assume that models update the ice coverage with time, and I bet they use data assimilation to self-correct to the past. This must be one reason why model projections for the future are so uncertain, since the albedo feedback of reduced ice coverage is divergent. Any small error in feedbacks gives large future temperature response.
Hi Clive,
Vial et al (doi: 10.1007/s00382-013-1725-9 ) estimate feedback parameters for some models and the total albedo effect is about 0.30+-0.07 W m-2 K-1 in CMIP5. For comparison, cloud feedbacks are approx. 0.35+-0.45 W m-2 K-1 and water vapour+lapse rate 1.00+-0.07 W m-2 K-1. The cloud contribution to the spread is 9 times greater than the albedo so I’d expect it to dominate. Especially since the albedo feedback includes a contribution from the ~30 million sq km of northern hemisphere spring snowpack.
Also, I’m pretty sure there’s no assimilation to correct ice extent in the CMIP5 historical simulations. That’s why you get papers like Stroeve et al. 2012 (doi: 10.1029/2012GL052676 ) and Shu et al. 2015 (doi: 10.5194/tc-9-399-2015 ).
As for the effect of sea ice change, Cowtan et al.’s Figure 3 lets you pick out what things have an effect. There’re combinations of variable and fixed ice, masked and unmasked, it looks to me like there’s a consistent blending effect, regardless of how you handle ice, masking or anomalies. There’s also an ice-edge effect if you use the anomaly approach (where you calculate anomalies for air and water temperatures separately), but if you blend before calculating the anomaly then the result is not very sensitive to the ice edge. Unfortunately for those of us who’ve used HadCRUT4, its techniques result in about the largest cool bias you can get.
Hi Mark,
Yes I agree that the models predict an increasing divergence between the blended (measured) and the calculated tas temperature anomalies , with minor differences in methodology (masking/ absolutes). However, the effect so far (2015) is still extremely small ~ 0.05C which is still within the Hadcrut4 measurement error ( Figure 4a). Figure 4b is consfusing as it mixes in an extra hypothetical aerosol reduction in CO2 forcing. At first sight figure 4b appears to show that the blending bias alone could explain away the hiatus, but this is simply untrue.
What I think should be done instead is to correct the Hadcrut4 ‘raw’ measurements for this bias (as is done for other baiases) and then compare the result to the raw CMIP5 tas predictions. We know that discrete measurements of SST by buoys and ships are made at precise locations. No HadSST3 measurements are done (as far as I know) over ice. These measurements are converted to anomalies relative to 1961-1990 normals and binned in a 5×5 degree grid. Each grid cell is averaged and the global weighted Hadcrut4 average made combined with CRUTEM4 land measurements.
To correct each SST measurement to TAS values, you would simply multiply by a factor TAS/TOS derived from models for that (lat,lon) and that month. Then Hadcrut4 would measure the global average for TAS and not some blended value. This would in my opinuon be a better way to compare apples with apples.
Hi Clive,
Figure 3 in the paper shows that the total HadCRUT4 method difference is a total of ~0.09K in 2014, relative to the start of the record, which is about the same as the observational uncertainties. Figure 4b shows the combined effect of the blending and the forcing differences (which do NOT include the aerosol contribution – see the text) and that these combined effects are around 2/3 of the difference between multi-model mean and observations. The blending procedure alone is the top panel – Fig. 4a.
Am surprised that you are advocating changing HadCRUT4 using models! The key point is that each model produces a slightly different correction, so it is a far better & cleaner comparison to use the individual model corrections for each model and compare to existing observational records, rather than correct the observations with an estimate of the multi-model mean.
cheers,
Ed.
Hi Ed,
Sorry, but I don’t think Figure 4b has any relevance at all to the paper in question. It folds in the results from a completely separate study to seemingly explain away the hiatus. Unfortunately this has been interpreted in the press as one of the conclusions of this paper. I myself was mislead as well. To quote.
The ‘robust’ conclusions (which I agree) with are that :
The point I am trying to make is that HADSST3 is only measured over ice free oceans, which individually can be corrected to TAS values using model results for that location. You cannot compare climate models to places where there are no measurements, nor should you be tempted to extrapolate them. Before 1900 global coverage of temperature measurements was < 15%. Does that mean we should replace the other 85% of the earth with modelling results?
Hi Clive,
Firstly, the paper is about like-with-like comparisons of observations and models. One aspect is ensuring forcings are represented appropriately, which was already considered by Schmidt & others. Another (new) aspect is the observation-type work done by Cowtan et al. There is nothing wrong with combining the older and new results in a single figure (Fig. 4b) to demonstrate the best like-with-like comparison possible.
And, of course we should not replace blank locations with modelling results – I never implied anything like that, and it is not what is done. Here we are deleting model data to compare with the direct observations where available – I don’t see why this is controversial.
What confuses me is that normally you have little faith in the models, but now you want to correct observations with modelled output?
cheers,
Ed.
I have redone the analysis using Kevin Cowtan’s code. I thank him for his help. He has done a thorough job and the calculations all look good to me. However, so far (2015) the bias is really rather small (0.03C) and still lies within measurement errors of Hadcrut4. The bias in temperature anomaly is simply proportional to the net warming since 1961-1990. By 2100 it reaches ~0.2C assuming temperaures rise 4C by then, and of course that the models are correct.
http://clivebest.com/blog/?p=6788
Mr. Hawkins,
With regard to the figure above, do you know if there is an extrapolation through to 2040 (or further) for the Updated Forcings graph, for the RCP8.5 simulation using the blended temperatures?
thanks
jinnah
Hi Jinnah,
Unfortunately that is not possible because we don’t know what the true forcings will be up to 2040. The graph ends in 2013 because that is the last date we have published estimates of the observed forcings.
Thanks,
Ed.